Giới thiệu
Trong bài viết này, chúng ta sẽ thử nhận diện khuôn mặt với tính ứng dụng rất cao trong máy học. Ngay cả ở công ty mình cũng có nhưng cũng không rõ là mức độ chính xác đến mức nào. Qua bài viết này bạn sẽ học được cách mà một khuôn mặt được nhận diện và cách để chúng ta qua mặt được các hệ thống nhận diện khuôn mặt với các điểm yếu của nó.
MTCNN và FaceNet là 2 mạng rất nổi tiếng trong việc xử lý bài toán Face Recognition nói chung. Và việc kết hợp giữa chúng, khi đầu vào là ảnh/video với rất nhiều người và trong hoàn cảnh thực tế, sẽ đưa ra được kết quả khá tốt. Khi đó, MTCNN sẽ đóng vai trò là Face Detection/Alignment, giúp cắt các khuôn mặt ra khỏi khung hình dưới dạng các tọa độ bounding boxes và chỉnh sửa / resize về đúng shape đầu vào của mạng FaceNet. Còn FaceNet sẽ đóng vai trò là mạng Feature Extractor + Classifier cho từng bounding boxes, đưa ra embedding và tiền hành phân biệt và nhận dạng các khuôn mặt.
Phạm vi của bài viết này sẽ tập trung ghi lại và thực hành những nội dung như sau :
- Nghiên cứu sử dụng dataset bao gồm hình ảnh của những người bất kì và một số người khác bạn muốn chọn bao nhiêu thì tuỳ ý, mỗi người chụp thẳng 20 bức ảnh.
- Lựa chọn các gói thư viện để phát hiện gương mặt và trích xuất gương mặt từ ảnh.
- Tạo Embedding từ hình ảnh sang vector.
- Xây dựng model để so sánh sự tương đồng giữa các bức ảnh, sử dụng tripleloss
- Đánh giá mô hình.
- Xây dựng giao diện người dùng để kiểm tra và hiển thị kết quả.
1.MTCNN
Mạng MTCNN hay Multi-Task Cascaded Convolutional Neural Networks là một mạng thần kinh giúp phát hiện khuôn mặt và các điểm khuôn mặt trên hình ảnh. Nó được xuất bản vào năm 2016 bởi Zhang et al. MTCNN ngoài việc được sử dụng để phát hiện khuôn mặt có thể được dùng để detect các object khác như biển số, xe… MTCNN bao gồm 3 mạng NN hay có thể gọi là 3 stages là P-Net, R-Net và O-Net (PRO!)
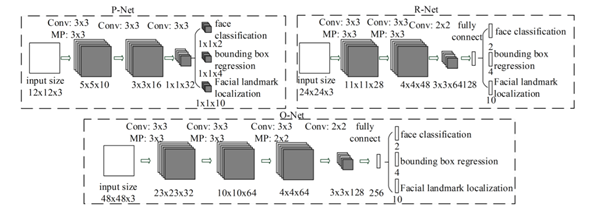
Ba nhiệm vụ chính của MTCNN là :
1.Face classification. 2.Bounding box regression. 3.Facial landmark localization.
1.2 The Proposal Network (P-Net)
Ở bước đầu tiên sẽ sử dụng mạng FCN (Fully Convolutional Network). Mạng FCN khác mạng CNN ở chỗ mạng FCN không sử dụng lớp Dense layer. P-Net được sử dụng để có được các bounding box tiềm năng và toạ độ của các bounding box Bounding box regression là kỹ thuật để dự đoán vị trí của bounding box khi chúng ta cần phát hiện đối tượng (ở đây là khuôn mặt). Sau khi có được tọa độ của bounding boxes một vài tinh chỉnh được thực hiện để loại bỏ một số bounding boxes trùng lấp với nhau. Đầu ra của bước này là tất cả bounding boxes sau khi đã thực hiện sàng lọc.
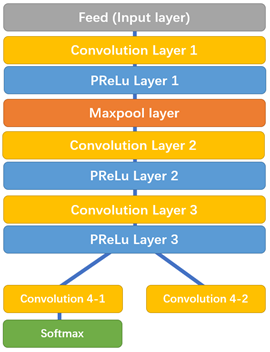
Ở đây có dùng PRelu layer (nói đơn giản giá trị không âm thì giữ nguyên, giá trị âm sẽ được nhân với hệ số, hệ số này được học trong quá trình training), bạn có thể xem chi tiết tại đây https://keras.io/api/layers/activation_layers/prelu/
Chú ý sau PReLu layer 3 tách thành 2 nhánh, nhánh 4-2 dùng để dự đoán tọa độ của bounding box, nhánh 4-1 dùng để dự đoán xác suất xuất hiện khuôn mặt trong bounding box.
1.3 The Refine Network (R-Net)
Tất cả bounding boxes từ P-Net được đưa vào R-Net. Chú ý rằng R-Net là mạng CNN chứ không phải FCN. R-Net giảm số lượng bounding boxes xuống, tinh chỉnh lại tọa độ, có áp dụng Non-max suppression. Ở đây cũng có 2 nhánh để dự đoán xuất hiện khuôn mặt hay không và tọa độ của bounding boxes. Chú ý: có một số phiên bản sửa đối ví dụ như ở R-Net có xác định facial landmarks, khi nói chúng ta sẽ đề cập đến một kiến trúc cụ thể.
Đầu ra của R-Net được sử dụng làm đầu vào của O-Net. Trong O-Net có đưa ra vị trí của facial landmarks (2 mắt, mũi, 2 vị trí của miệng). Như hình trên có thể thấy gần cuối chúng ta có 3 nhánh: xác suất xuất hiện khuôn mặt, tọa độ bounding box, tọa độ của facial landmarks (mỗi vị trí có tọa độ x và y, cái này ảnh hưởng đến số lượng units trong layer).
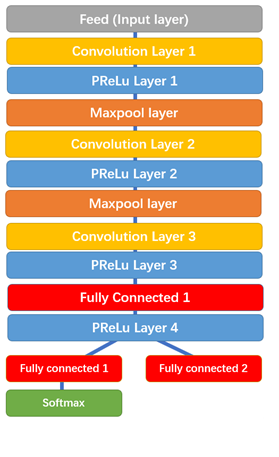
1.4. The Output Network (O-Net)
Đầu ra của R-Net được sử dụng làm đầu vào của O-Net. Trong O-Net có đưa ra vị trí của facial landmarks (2 mắt, mũi, 2 vị trí của miệng). Như hình trên có thể thấy gần cuối chúng ta có 3 nhánh: xác suất xuất hiện khuôn mặt, tọa độ bounding box, tọa độ của facial landmarks (mỗi vị trí có tọa độ x và y, cái này ảnh hưởng đến số lượng units trong layer).
2. Facenet-Pytorch
2.1. Giới thiệu Facenet Pytouch
FaceNet là một mạng thần kinh sâu được sử dụng để trích xuất các đặc điểm từ hình ảnh khuôn mặt của một người. Nó được xuất bản vào năm 2015 bởi các nhà nghiên cứu Google Schroff et al. FaceNet lấy hình ảnh khuôn mặt của một người làm đầu vào và xuất ra một vectơ gồm 128 chiều thể hiện những đặc điểm quan trọng nhất của khuôn mặt.
Trong học máy, vectơ này được gọi là nhúng (embedding) . Tại sao phải embedding? Bởi vì tất cả thông tin quan trọng từ một hình ảnh đều được embedding vào vector này. Về cơ bản, FaceNet lấy khuôn mặt của một người và nén nó thành một vector gồm 128 chiều. Việc embedding các khuôn mặt cũng theo cách làm tương tự như vậy.
Một cách có thể để nhận ra một người trên một hình ảnh không biết là tính toán các embedding của nó, tính toán khoảng cách tới hình ảnh của những người đã biết và nếu khuôn mặt embedding đủ gần để embedding người A, chúng ta nói rằng hình ảnh này chứa khuôn mặt của người A.
2.2. Cách hoạt động
1.Chọn ngẫu nhiên một neo (anchor) hình ảnh. 2.Chọn ngẫu nhiên một hình ảnh của cùng một người làm anchor hình ảnh. 3.Chọn ngẫu nhiên hình ảnh của một người khác với anchor hình ảnh . 4.Điều chỉnh các tham số của mạng FaceNet để tìm ra 5.Lặp lại quá trình đến khi không có nhiều thay đổi nữa, điều này cũng đồng nghĩa với việc các khuôn mặt của một người được sắp xếp gần nhau.
2.3. Các khái niệm cơ bản
Embedding Vector: Là một vector với dimension cố định (thường có chiều nhỏ hơn các Feature Vector bình thường), đã được học trong quá trình train và đại diện cho một tập các feature có trách nhiệm trong việc phân loại các đối tượng trong chiều không gian đã được biến đổi. Embedding rất hữu dụng trong việc tìm các Nearest Neighbor trong 1 Cluster cho sẵn, dựa theo khoảng cách-mối quan hệ giữa các embedding với nhau.
Inception V1: Một cấu trúc mạng CNN được giới thiệu vào năm 2014 của Google, với đặc trưng là các khối Inception. Khổi này cho phép mạng được học theo cấu trúc song song, nghĩa là với 1 đầu vào có thể được đưa vào nhiều các lớp Convolution khác nhau để đưa ra các kết quả khác nhau, sau đó sẽ được Concatenate vào thành 1 output. Việc học song song này giúp mạng có thể học được nhiều chi tiết hơn, lấy được nhiều feature hơn so với mạng CNN truyền thống. Ngoài ra, mạng cũng áp dụng các khối Convolution 1x1 nhằm giảm kích thước của mạng, khiến việc train trở nên nhanh hơn.
3. Open CV
3.1. Giới thiệu OpenCV
OpenCV(Open Source Computer Vision) là một thư viện mã nguồn mở bao gồm hàng trăm thuật toán thị giác máy tính. Với mục đích của bài toán này, opencv được sử dụng phổ biến trong việc căn chỉnh và thay đổi các kích thước ảnh, đồng thời xử lí các thông tin nhiễu của bức ảnh làm tăng độ chính xác đối với mô hình đào tạo.
3.2. Các module được dùng trong OpenCV
OpenCV có cấu trúc module, tức là nó bao gồm cả những thư viện liên kết tĩnh lẫn thư viện liên kết động. Nắm rõ các module của OpenCV sẽ giúp bạn đọc hoàn toàn thấu hiểu OpenCV là gì.
Core functionality (core): Module này sở hữu cơ chế rất nhỏ gọn. Nó được dùng để định hình các cấu trúc của cơ sở dữ liệu cơ bản, bao gồm cả những mảng đa chiều. Ngoài ra nó còn xác định các chức năng của những module đi kèm khác nữa.
Image Processing (imgproc): Đây là module được dùng cho quá trình xử lý hình ảnh. Nó cho phép người dùng thực hiện các hoạt động như lọc hình ảnh tuyến tính và phi tuyến, thực hiện phép biến hình, thay đổi không gian màu, xây dựng biểu đồ và rất nhiều thao tác khác liên quan.
Video Analysis (video): Giống như tên gọi của nó, module này cho phép phân tích các video. Kết quả được trả về bao gồm các ước tính chuyển động, thực hiện tách nền và các phép toán theo dõi vật thể.
Camera Calibration and 3D Reconstruction (calib3d): Module này cung cấp các thuật toán hình học đa chiều cơ bản và hiệu chuẩn máy ảnh single và stereo. Ngoài ra nó còn đưa ra các dự đoán kiểu dáng của đối tượng và sử dụng thuật toán thư tín âm thanh nổi cùng các yếu tố tái tạo 3D.
2D Features Framework (features2d): Module này giúp phát hiện các tính năng nổi trội của bộ nhận diện, bộ truy xuất thông số và thông số đối chọi.
Ngoài ra còn có rất nhiều module khác với đa dạng tính năng, ví dụ như: FLANN, Google test wrapper…
3.3. Ứng dụng của OpenCV
Nhờ một hệ thống các giải thuật chuyên biệt, tối ưu cho việc xử lý thị giác máy tính, vì vậy tính ứng dụng của OpenCV là rất lớn, có thể kể đến như:
- Nhận dạng ảnh.
- Xử lý hình ảnh.
- Phục hồi hình ảnh/video.
- Thực tế ảo.
- Các ứng dụng khác.
4. Streamlit
Streamlit là một thư viện Python mã nguồn mở giúp dễ dàng tạo và chia sẻ các ứng dụng web đẹp, tùy chỉnh cho máy học và khoa học dữ liệu. Chỉ trong vài phút, có thể xây dựng và triển khai các ứng dụng dữ liệu mạnh mẽ.Những ưu điểm phải kể đến của thư viện này:
- Miễn phí: Streamlit cung cấp demo miễn phí một app cho tất cả mọi người.
- Cộng đồng mạnh mẽ.
- Đơn giản dễ viết.
- Tài liệu đủ tốt.
Nhận diện khuôn mặt
1. Dữ liệu
Dữ liệu chuẩn bị, đây là một điểm yếu chết người trong máy học, nếu bạn không có đủ dữ liệu và dữ liệu thiếu chính xác, đó là một điểm yếu. Mỗi thư mục sẽ đại diện cho một người được đào tạo với tên thư mục chính là tên của người đào tạo, còn bên trong là các ảnh gốc được chụp ở các góc khác nhau.
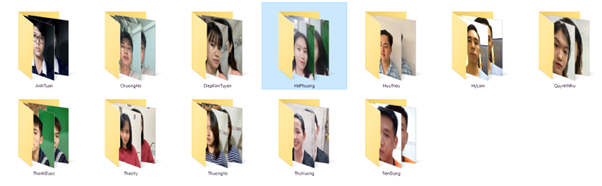
Bên trong thư mục của mỗi nhân vật sẽ được chứa toàn bộ các bức ảnh của nhân vật đó ứng với mỗi tấm với các góc cạnh khác nhau, và sau này bạn có thể dễ dàng thêm mới dữ liệu của nhân vật đó vào vị trí này.

2. Làm sạch dữ liệu
Việc làm sạch khuôn mặt nhằm loại bỏ các bức ảnh xấu khỏi dữ liệu, các ảnh xấu dưới đây sẽ được loại bỏ khỏi mô hình đào tạo như:
Khuôn mặt quá mờ không rõ nét.
Hình ảnh không có khuôn mặt.
Khoảng cách khuôn mặt quá xa.
3. Phát hiện khuôn mặt
Khuôn mặt được phát hiện sử dụng mạng MTCNN tính từ trái qua phải:
Ảnh gốc (1)
Khuôn mặt được phát hiện với đường bao hình chữ nhật(2)
Landmarks của khuôn mặt và khung bao khuôn mặt tìm thấy, bao gồm các vị trí : 2 khóe miệng, mũi, hai mắt.(3)
3.1. Phát hiện khuôn mặt
Có rất nhiều phương pháp để phát hiện khuôn mặt như Haar cascades, Single Shot Multibox Detector (SSD) trong OpenCV dưới dạng pre-trained model, Dlib có HOG và CNN (hay còn gọi là Max-Margin Object Detection MMOD). Ngoài ra còn phải kể đến MTCNN (multi-task Cascaded Convolutional Networks) và RetinaFace là những mô hình rất tiên tiến để phát hiện khuôn mặt. Trong bài này sẽ sử dụng mạng MTCNN như đã giới thiệu ở phần phát hiện khuôn mặt (3).
from mtcnn import MTCNN
import cv2
from skimage import io
import matplotlib.pyplot as plt
from mtcnn import MTCNN
import cv2
from skimage import io
import matplotlib.pyplot as plt
# show image normal
img = io.imread("dataset/257991666_336352071587671_6814217796597557227_n.jpg")
plt.imshow(img)
detector = MTCNN()
# detect faces in the image
results = detector.detect_faces(img)
results
3.2 Phát hiện mắt trong ảnh.
Với thư viện mtcnn, cũng dễ dàng nhận biết được hai mắt, mũi và vị trí của hai khoé miệng.
# import lib
from mtcnn import MTCNN
import cv2
from skimage import io
import matplotlib.pyplot as plt
# show image normal
img = io.imread("dataset/257991666_336352071587671_6814217796597557227_n.jpg")
plt.imshow(img)
detector = MTCNN()
# detect faces in the image
results = detector.detect_faces(img)
## show boundingbox
for i in range(len(results)):
x1, y1, width, height = results[i]['box']
x2, y2 = x1 + width, y1 + height
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
plt.imshow(img)
# Show full landmark and bounding box
bounding_box = results[0]['box']
keypoints = results[0]['keypoints']
display(bounding_box, keypoints)
def showimage(results):
for person in results:
bounding_box = person['box']
keypoints = person['keypoints']
#draw bounding box
cv2.rectangle(img,
(bounding_box[0], bounding_box[1]),
(bounding_box[0]+bounding_box[2], bounding_box[1]+bounding_box[3]), (0,155,255), 1)
#draw keypoints
for key in keypoints.keys():
cv2.circle(img, (keypoints[key][0], keypoints[key][1]), 15, (0,155,255), 5)
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.show()
showimage(results)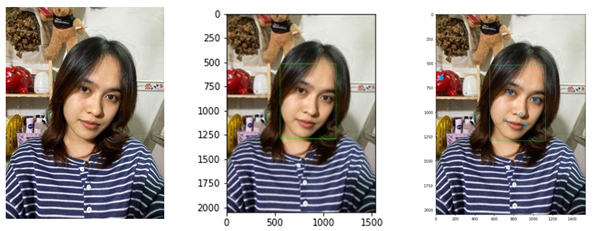
5. Tăng cường dữ liệu
Nhằm cho tăng cường sự chính xác khi nhận diện khuôn mặt, việc căn chỉnh các góc cạnh của khuôn mặt là vô cùng cần thiết. Face alignment là quá trình sắp xếp khuôn mặt sao cho nó thẳng đứng trong ảnh. Face alignment thường được thực hiện như bước tiền xử lý cho các thuật toán nhận diện khuôn mặt. Để thực hiện việc này cần trải qua 2 bước:
- Xác định cấu trúc hình học của khuôn mặt trong ảnh.
- Thực hiện face alignment thông qua các pháp biến đổi như translation (dịch chuyển), scale, rotation.
Có một số phương pháp để thực hiện face alignment như sử dụng pre-trained 3D model sau đó chuyển ảnh đầu vào sao cho các landmarks trên khuôn mặt ban đầu khớp với landmarks trên 3D model… Trong bài này chúng ta sẽ thực hiện face alignment dựa trên vị trí của hai mắt.
Dưới đây là các bước thực hiện face alignment:
- Phát hiện khuôn mặt và mắt trong ảnh
- Xác định tâm của hai mắt, vẽ đường nối hai tâm
- Vẽ đường nằm ngang giữa hai mắt, tính góc xoay ảnh
- Xoay ảnh
- Scale ảnh
Vì việc sử dụng mtcnn đã giúp chúng ta giải quyết được hàng loạt các điểm thắt trong việc phát hiện khuôn mặt và mắt ảnh , vì vậy chúng ta sẽ tiếp tục đi đến các vấn đề như xác định mắt trái phải và tìm cách cải thiện chúng.
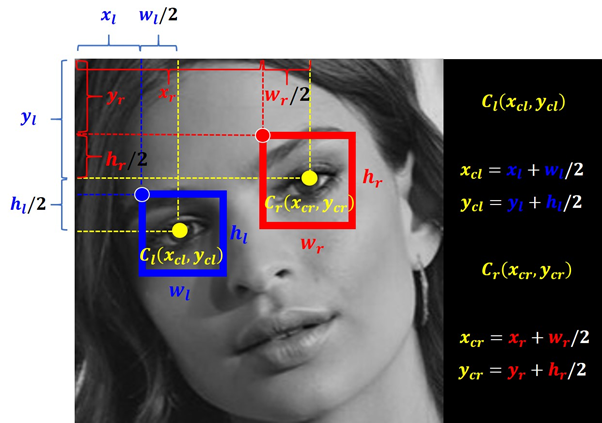
5.1. Xác định tâm của hai mắt, vẽ đường nối hai tâm
Đầu tiên sẽ xác định mắt nào là mắt trái, mắt nào là mắt phải (đứng từ phía người dùng) dựa trên tọa độ x của hai bounding box quanh mắt. Sau đó chúng ta đi xác định tâm của hai mắt (coi là tâm của 2 bounding boxes), dễ dàng vẽ được đoạn thẳng nối hai tâm.
import tensorflow
from mtcnn import MTCNN
import cv2
import os
import glob
import numpy as np
from tqdm import tqdm
import shutil
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
def align(img):
# This function takes in an image, detects the bounding boxes for the face or faces
# in the image and then selects the face with the largest number of pixels.
# for the largest face the eye centers are detected and the angle of the eyes with respect to
# the horizontal axis is determined. It then provides this angle to the rotate_bound function
# the rotate_bound function the rotates the image so the eyes are parallel to the horizontal axis
data=detector.detect_faces(img)
# In case the image has more than 1 face, find the biggest face
biggest=0
if data !=[]:
for faces in data:
box=faces['box']
# calculate the area in the image
area = box[3] * box[2]
if area>biggest:
biggest=area
bbox=box
keypoints=faces['keypoints']
left_eye=keypoints['left_eye']
right_eye=keypoints['right_eye']
lx,ly=left_eye
rx,ry=right_eye
dx=rx-lx
dy=ry-ly
tan=dy/dx
theta=np.arctan(tan)
theta=np.degrees(theta)
img=rotate_bound(img, theta)
return (True,img)
else:
return (False, None)5.2 Vẽ đường nằm ngang giữa hai mắt, tính góc xoay ảnh
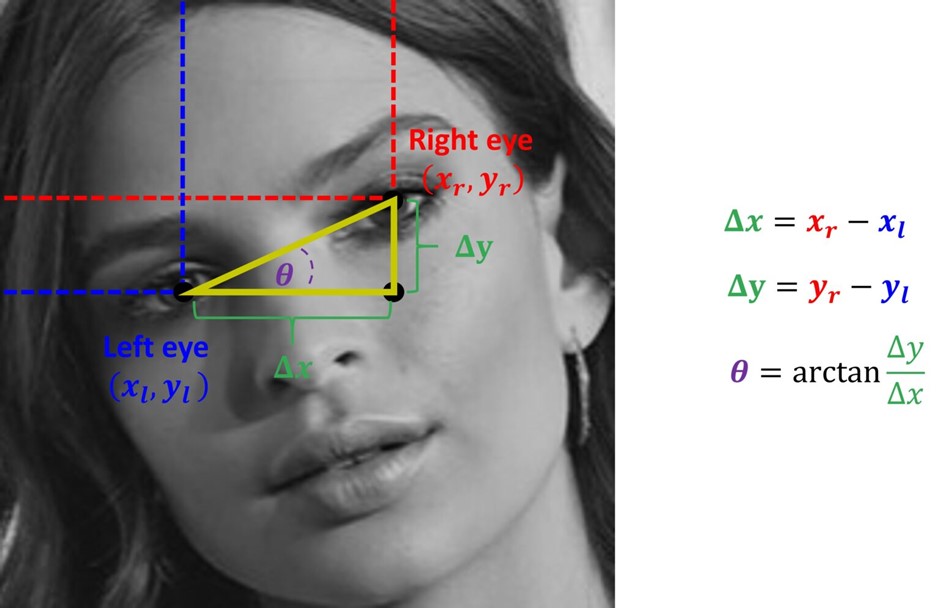
Xác định tâm mắt bên nào nằm dưới dựa vào tọa độ y, đồng thời vẽ điểm A để phục vụ cho việc tính góc xoay. Ở đây cần chú ý cả chiều xoay:
- Nếu mắt trái (nhìn từ phía người dùng) thấp hơn mắt phải, chúng ta sẽ phải xoay ảnh theo chiều kim đồng hồ.
- Nếu mắt phải (nhìn từ phía người dùng) thấp hơn mắt trái, chúng ta phải xoay ảnh theo chiều ngược kim đồng hồ.
5.3 Xoay ảnh
def rotate_bound(image, angle):
#rotates an image by the degree angle
# grab the dimensions of the image and then determine the center
(h, w) = image.shape[:2]
(cX, cY) = (w // 2, h // 2)
# grab the rotation matrix (applying the angle to rotate clockwise), then grab the sine and cosine
# (i.e., the rotation components of the matrix)
M = cv2.getRotationMatrix2D((cX, cY), angle, 1.0)
cos = np.abs(M[0, 0])
sin = np.abs(M[0, 1])
# compute the new bounding dimensions of the image
nW = int((h * sin) + (w * cos))
nH = int((h * cos) + (w * sin))
# adjust the rotation matrix to take into account translation
M[0, 2] += (nW / 2) - cX
M[1, 2] += (nH / 2) - cY
# perform the actual rotation and return the image
return cv2.warpAffine(image, M, (nW, nH))Kết quả sau khi thực hiện căn chỉnh và xoay, khuôn mặt sau khi được căn chỉnh để hỗ trợ việc nhận diện tốt hơn trong mô hình.Có thể thấy một số bức ảnh dù chụp nghiêng cũng đã được xoay chỉnh đúng với góc cạnh khuôn mặt.
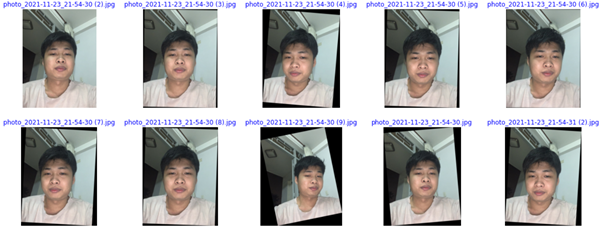
5.4. Crop ảnh
Kết quả sau khi thực hiện căn chỉnh và xoay, khuôn mặt sau khi được căn chỉnh để hỗ trợ việc nhận diện tốt hơn trong mô hình. Có thể thấy một số bức ảnh dù chụp nghiêng cũng đã được xoay chỉnh đúng với góc cạnh khuôn mặt. Việc rop ảnh đảm bảo rằng chúng ta có thể tăng khả năng dự đoán của gương mặt với các pixel dựa vào khung xung quanh khuôn mặt
def crop_image(img):
data=detector.detect_faces(img)
#y=box[1] h=box[3] x=box[0] w=box[2]
biggest=0
if data !=[]:
for faces in data:
box=faces['box']
# calculate the area in the image
area = box[3] * box[2]
if area>biggest:
biggest=area
bbox=box
bbox[0]= 0 if bbox[0]<0 else bbox[0]
bbox[1]= 0 if bbox[1]<0 else bbox[1]
img=img[bbox[1]: bbox[1]+bbox[3],bbox[0]: bbox[0]+ bbox[2]]
return (True, img)
else:
return (False, None)
def align_crop_resize(sdir,dest_dir, height=None, width= None):
# This function takes in a source directory and destination directory
aligned_dir, cropped_dir = create_folder(dest_dir)
flist=os.listdir(sdir) #get a list of the image files
success_count=0
for user in flist:
for file in glob.glob(os.path.join(sdir, user)+'/*.jpg'):
try:
img=cv2.imread(file) # read in the image
shape=img.shape
status,img=align(img) # rotates the image for the eyes are horizontal
if status:
aligned_path_user=os.path.join(aligned_dir,user)
if(os.path.exists(aligned_path_user)==False): os.mkdir(aligned_path_user)
id_mark = os.path.basename(file)
img_outputname = os.path.join(aligned_path_user, id_mark)
cv2.imwrite(img_outputname, img)
cstatus, img=crop_image(img) # crops the aligned image to return the largest face
if cstatus:
if height != None and width !=None:
img=cv2.resize(img, (height, width)) # if height annd width are specified resize the image
cropped_path_user=os.path.join(cropped_dir, user)
if os.path.exists(cropped_path_user)==False: os.mkdir(cropped_path_user)
id_mark = os.path.basename(file)
img_outputname = os.path.join(cropped_path_user, id_mark)
cv2.imwrite(img_outputname, img) # save the image
success_count +=1 # update the coount of successful processed images
except Exception as e:
print('file ', file, ' is a bad image file')
return success_count
6. Nhận diện khuôn mặt
6.1. Đào tạo mô hình
Hầu hết chúng ta khi xây dựng một thuật toán nhận diện khuôn mặt sẽ không cần phải train lại mô hình FaceNet mà tận dụng lại các mô hình pretrain sẵn có. Những mô hình pretrain được huấn luyện trên các dữ liệu lên tới hàng triệu ảnh. Do đó có khả năng mã hóa rất tốt các bức ảnh trên không gian 128 chiều. Việc còn lại của chúng ta là sử dụng lại mô hình, tính toán embedding véc tơ và huấn luyện embedding véc tơ bằng một classifier đơn giản để phân loại classes.
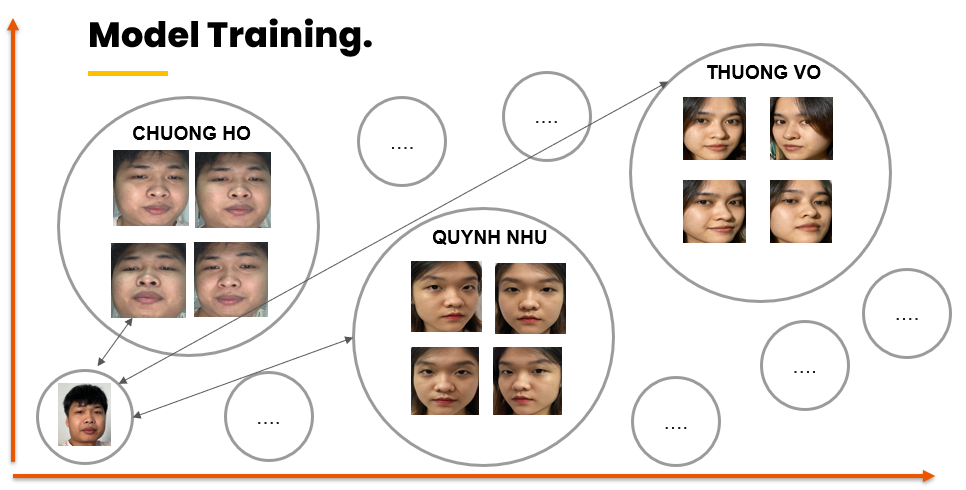
Quá trình đào tạo mô hình được mô tả như sau :
Sử dụng một tập Dataset với rất nhiều các cá thể người khác nhau, mỗi cá thể có một số lượng ảnh nhất định.
Xây dựng một mạng DNN dùng để làm Feature Extractor cho Dataset trên, kết quả là 1 embedding 128-Dimensions. Trong paper có 2 đại diện mạng là Zeiler&Fergus và InceptionV1.Ở đây sẽ sử dụng mạng
InceptionV1 với hai pretrained là VGGFace2 và CASIA-WebFace.Trong bài báo cáo này sẽ sử dụng bộ dữ liệu VGGFace2 gồm khoảng 3 triệu ảnh được thu thập từ gần 9k người để làm việc.

Bước cuối cùng là Lưu trữ mô hình bao gồm dữ liệu các embedding và các tên của các khuôn mặt được lấy từ tên của thư mục chính đại diện trong dataset.
from facenet_pytorch import MTCNN, InceptionResnetV1
import torch
from torchvision import datasets
from torch.utils.data import DataLoader
from PIL import Image
import cv2
import time
import os
import shutil
import matplotlib.pyplot as plt
# initializing MTCNN and InceptionResnetV1
mtcnn0 = MTCNN(image_size=240, margin=0, keep_all=False, min_face_size=40) # keep_all=False
mtcnn = MTCNN(image_size=240, margin=0, keep_all=True, min_face_size=40) # keep_all=True
resnet = InceptionResnetV1(pretrained='vggface2').eval()
path_flag = os.path.exists('data.pt')
if path_flag:
load_data = torch.load('data.pt')
embedding_list = load_data[0]
name_list = load_data[1]
else:
embedding_list = []
name_list = []
# Update Data From Folder
fartherFolder = 'photos_aligned/Aligned Images'
fartherCroped = 'photos_aligned/Cropped_Images'
database_folder = "photos_database"
people_count = len(os.listdir(fartherFolder))
def collate_fn(x):
return x[0]
def moveFolderInfolder(fartherFolder,des):
folders = os.listdir(fartherFolder)
if(len(folders)>0):
for folder in folders:
shutil.move(fartherFolder+'/'+folder, des)
return folders
if(people_count > 0):
dataset = datasets.ImageFolder(fartherFolder) # photos folder path
idx_to_class = {i:c for c,i in dataset.class_to_idx.items()} # accessing names of peoples from folder names
loader = DataLoader(dataset, collate_fn=collate_fn)
for img, idx in loader:
face, prob = mtcnn0(img, return_prob=True)
if face is not None and prob>0.92:
emb = resnet(face.unsqueeze(0))
embedding_list.append(emb.detach())
name_list.append(idx_to_class[idx])
#move folder photos to database folder
moveFolderInfolder(fartherFolder,database_folder)
# save data
data = [embedding_list, name_list]
torch.save(data, 'data.pt') # saving data.pt file
print(f"{people_count} new people added to database")6.2. So sánh và dự đoán gương mặt
Bằng cách sử dụng thư viện FaceNet như đã trình bày để tính toán khoảng cách embedding giữa một khuôn mặt mới và các khuôn mặt đã biết, khoảng cách càng nhỏ độ chính xác càng cao.
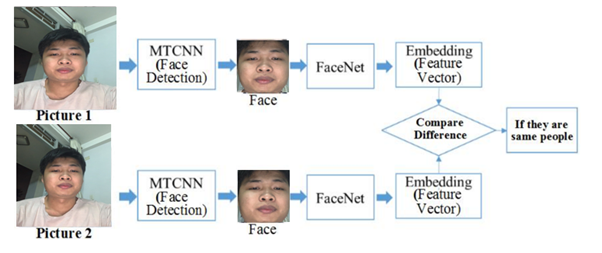
Mô tả chi tiết trực tiếp tổng thế so với dữ liệu hiện có như sau :
load_data = torch.load('data.pt')
embedding_list = load_data[0]
name_list = load_data[1]
# power = 1
def predict_face(img):
data_peoples = []
min_dist = 0
img_cropped_list, prob_list = mtcnn(img, return_prob=True)
if img_cropped_list is not None:
boxes, _ = mtcnn.detect(img)
name_peoples = []
box_peoples = []
min_dist_list = []
count_Unknown = 0
if boxes is not None:
# for box in boxes:
for i, prob in enumerate(prob_list):
if prob > 0.90:
emb = resnet(img_cropped_list[i].unsqueeze(0)).detach()
dist_list = [] # list of matched distances, minimum distance is used to identify the person
for idx, emb_db in enumerate(embedding_list):
dist = torch.dist(emb, emb_db).item()
dist_list.append(dist)
min_dist = min(dist_list) # get minumum dist value
min_dist_idx = dist_list.index(
min_dist) # get minumum dist index
box = boxes[i] # get box of face
if(min_dist < 0.90):
# get name corrosponding to minimum dist
name = name_list[min_dist_idx]
else:
name = "Unknown" # get name corrosponding to minimum dist
count_Unknown += 1
if(count_Unknown > 100):
bbox = list(map(int,box.tolist()))
img = cv2.rectangle(img, (bbox[0],bbox[1]), (bbox[2],bbox[3]), (0,0,255), 2)
img = cv2.putText(img, name + '_{:.2f}'.format(dist), (bbox[0],bbox[1]), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,255,0), 1, cv2.LINE_8)
break
box_peoples.append(box)
name_peoples.append(name)
min_dist_list.append(min_dist)
#score = (torch.Tensor.cpu(min_dist.detach().numpy()*power))
bbox = list(map(int,box.tolist()))
img = cv2.rectangle(img, (bbox[0],bbox[1]), (bbox[2],bbox[3]), (0,0,255), 2)
img = cv2.putText(img, name + '_{:.2f}'.format(min_dist), (bbox[0],bbox[1]), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,255,0), 1, cv2.LINE_8)
data_peoples = [name_peoples, box_peoples,min_dist_list]
return data_peoplesThử kiểm tra và dự đoán gương mặt
img_path = r"D:\test\chuongtest.jpg"
# img_path = r"D:\DATN_MachineLearning\live_face_recognition\test\trieutest.jpg"
#read image RGB
img = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (500, 660))
# cv2.imshow('RGB Image',img_rgb )
plt.imshow(img)
datapredicts = predict_face(img)
names = datapredicts[0]
Unknowns = len([i for i in names if i == "Unknown"])
print("Len Data Name Predicts:", len(datapredicts[0]))
print("Count Unknown:", Unknowns)
print("Count Known:", len(names)-Unknowns)
plt.imshow(img)
7. Cập nhật mô hình đào tạo
Mô hình đào tạo dễ dàng được thêm mới bằng cách đưa các dữ liệu người dùng với tên thư mục vào bộ dataset với quy trình như sau:
- Làm sạch dữ liệu mới đưa vào.
- Phát hiện gương mặt và tăng cường dữ liệu.
- Lấy về các embedding của dữ liệu gương mặt mới.
- Thêm các embeding mới vào mô hình đào tạo trước đó.
8. Giao diện người dùng kiêm thử
Bạn có thể thử một chút với streamlit và phát hành một ứng dụng nhận diện khuôn mặt cơ bản với bộ dữ liệu hiện có
import streamlit as st
from PIL import Image
from facenet_pytorch import MTCNN, InceptionResnetV1
import torch
from torchvision import datasets
from torch.utils.data import DataLoader
from PIL import Image
import cv2
import time
import os
from io import BytesIO
import base64
import numpy as np
import shutil
import matplotlib.pyplot as plt
#Create sample a app
st.title("Face Recognition Demo")
try:
uploaded_file = st.file_uploader("Upload a file image", type=["png","jpg","jpeg"])
if uploaded_file is not None:
st.image(uploaded_file, caption='Image uploaded', use_column_width=True, clamp=True)
except Exception as e:
st.write("Can't Show Image, Please Select Image Other To Show!")
def predict_face(img):
# initializing MTCNN and InceptionResnetV1
mtcnn0 = MTCNN(image_size=240, margin=0, keep_all=False, min_face_size=40) # keep_all=False
mtcnn = MTCNN(image_size=240, margin=0, keep_all=True, min_face_size=40) # keep_all=True
resnet = InceptionResnetV1(pretrained='vggface2').eval()
data_peoples = []
min_dist = 0
name_peoples = []
box_peoples = []
min_dist_list = []
img_cropped_list, prob_list = mtcnn(img, return_prob=True)
if img_cropped_list is not None:
boxes, _ = mtcnn.detect(img)
count_Unknown = 0
if boxes is not None:
# for box in boxes:
for i, prob in enumerate(prob_list):
if prob > 0.90:
emb = resnet(img_cropped_list[i].unsqueeze(0)).detach()
dist_list = [] # list of matched distances, minimum distance is used to identify the person
for idx, emb_db in enumerate(embedding_list):
dist = torch.dist(emb, emb_db).item()
dist_list.append(dist)
min_dist = min(dist_list) # get minumum dist value
min_dist_idx = dist_list.index(
min_dist) # get minumum dist index
box = boxes[i] # get box of face
if(min_dist < 1):
# get name corrosponding to minimum dist
name = name_list[min_dist_idx]
else:
name = "Unknown" # get name corrosponding to minimum dist
bbox = list(map(int,box.tolist()))
img = cv2.rectangle(img, (bbox[0],bbox[1]), (bbox[2],bbox[3]), (0,0,255), 2)
img = cv2.putText(img, name + '_{:.2f}'.format(min_dist), (bbox[0],bbox[1]), cv2.FONT_HERSHEY_SIMPLEX, 2, (0,255,0), 2, cv2.LINE_8)
break
# print("Name:", name)
# print("Min dist:", min_dist)
# print("Min dist idx:", min_dist_idx)
# print("idx", idx)
box_peoples.append(box)
name_peoples.append(name)
min_dist_list.append(min_dist)
#score = (torch.Tensor.cpu(min_dist.detach().numpy()*power))
bbox = list(map(int,box.tolist()))
img = cv2.rectangle(img, (bbox[0],bbox[1]), (bbox[2],bbox[3]), (0,0,255), 2)
img = cv2.putText(img, name + '_{:.2f}'.format(min_dist), (bbox[0],bbox[1]), cv2.FONT_HERSHEY_SIMPLEX, 2, (0,255,0), 2, cv2.LINE_8)
data_peoples = [name_peoples, box_peoples,min_dist_list]
return img,data_peoples
def get_image_download_link(img):
"""Generates a link allowing the PIL image to be downloaded
in: PIL image
out: href string
"""
buffered = BytesIO()
img.save(buffered, format="JPEG")
img_str = base64.b64encode(buffered.getvalue()).decode()
href = f'<a href="data:file/jpg;base64,{img_str}" download ="result.jpg">Download result</a>'
return href
if st.button('Start Predict'):
if uploaded_file is None :
st.write("Please upload an image")
else:
st.write("Start Predict")
st.write("Reading image...")
file_bytes = np.asarray(bytearray(uploaded_file.read()), dtype=np.uint8)
opencv_image = cv2.imdecode(file_bytes, 1)
st.write("Loaded data....")
dir_path = os.path.dirname(os.path.realpath(__file__))
load_data = torch.load(os.path.join(dir_path,"data.pt"))
embedding_list = load_data[0]
name_list = load_data[1]
imgpredict,data_peoples = predict_face(opencv_image)
st.write("Predicting...")
img = cv2.cvtColor(imgpredict, cv2.COLOR_BGR2RGB)
# img = cv2.resize(img, (500, 660))
st.image(img, caption=f"Image Predicted")
result = Image.fromarray(img)
st.markdown(get_image_download_link(result), unsafe_allow_html=True)Kết quả dự đoán có phần phụ thuộc nhiều vào bộ dữ liệu và mức độ chi tiết của khuôn mặt, khuôn mặt rõ ràng luôn cho kết quả khả quan.

9. Giới hạn và đề xuất cải tiến
Do ứng dụng được thử nghiệm trên Streamlit nên sẽ tồn đọng rất nhiều về giới hạn bộ nhớ và giao diện người dùng tùy chỉnh, vì vậy đây cũng có thể là một điểm trừ với ứng dụng này. Vì nghiên cứu cũng khá gò bó về thời gian nên các vấn đề về mã vẫn chưa được tối ưu hóa, sẽ tồn đọng một số lỗi.
Bước phân loại có thể được thực hiện bằng cách tính toán khoảng cách nhúng giữa một khuôn mặt mới và các khuôn mặt đã biết, nhưng cách tiếp cận đó quá tốn kém về mặt tính toán và bộ nhớ (phương pháp này được gọi là k-NN ). Thay vào đó, có thể sử dụng công cụ phân loại Softmax giúp ghi nhớ khoảng cách giữa ảnh của mỗi người người và hiệu quả hơn nhiều.
10. Kết luận
Kết quả mô hình khá khả quan có thể nhận diện được hầu hết tất cả các khuôn mặt được đào tạo,tuy nhiên vẫn còn tồn tại rất nhiều hạn chế như:
- Dữ liệu chưa đủ lớn để tào tạo mô hình chính xác nhất.
- Phần Classifier chủ yếu dựa vào các embedings khá giống với thuật toán KNN với k=1 cho nên kết quả chưa thực sự tốt đối với các ảnh bị mờ hay khoảng cách gương mặt quá xa.
Rõ ràng, nhận diện khuôn mặt bị giới hạn rất nhiều ở độ phân giải của bức ảnh và góc cạnh của khuôn mặt, thậm chí là sẽ khó khăn hơn với một người có màu da khác nhau hay mang kính râm. Điều đó cũng giúp cho bạn tìm ra cách để né tránh các nhận diện khuôn mặt và làm giảm khả năng của nó.
Dự án được công khai tại Face_Recognition bạn có thể xem xét đầy đủ để nghiên cứu thêm.
Tham khảo
https://github.com/timesler/facenet-pytorch
https://github.com/ipazc/mtcnn
https://github.com/maziarraissi/Applied-Deep-Learning
https://github.com/davidsandberg/facenet
https://arsfutura.com/magazine/building-a-face-recognition-powered-door-lock/