Giới thiệu
Lại một ngày cuối tuần lại trôi qua, trong khi đang mải mê ngồi săn sale, ngắm gái tây một mình đi trên đường phố Singapore, nhân tiện mạng khá mạnh nên mình quyết định thử cào hình ảnh của BIMObject để sử dụng và phân tích. Mục đích của bài này giúp bạn hiểu rõ cách cào một dữ liệu từ một trang web học thuật là chính. Việc sử dụng thông tin dữ liệu vào mục đích gì là do bạn quyết định.
Thông qua bài viết này sẽ giúp bạn từng bước tiếp cận vấn đề và cào dữ liệu ở quy mô nhỏ, cách nhìn nhận một vấn đề nhỏ để giải quyết mà không gặp bắt cứ khó khăn nào.
Internet là một kho dữ liệu khổng lồ của thế giới, bạn có thể lấy nhiều thứ hữu ích mà bạn cần, mọi trang web đều chứa riêng thông tin về một chủ đề nào đó. Nhưng đa số các dữ liệu trang web hầu như không mở sẵn để ai cũng dễ dàng lấy được và thường có các nơi lưu trữ cục bộ riêng cho một trang web. Việc am hiểu Scraping sẽ giúp bạn nhanh chóng thu thập các dữ liệu cần thiết, tiến hành tham gia phân tích cho một dự án hoặc nghiên cứu cho một dự án đặc thù nào đó.
Scraping hiểu đơn giản là trích xuất dữ liệu, tùy theo khả năng và mong muốn cách lấy thông tin dữ liệu mà các lập trình viên tạo ra. Và chúng được sử dụng để trích xuất thông tin từ các trang web, tệp html, các nơi chứa dữ liệu khác.
Trong học máy và phân tích dữ liệu, Scraping và Crawling là hai khái niệm khổ biến và cốt lõi, hãy thử tưởng tượng bạn đang làm học máy và phân tích dữ liệu mà không có dữ liệu hay bất cứ thứ gì để học hoặc phân tích. Giống như việc đi du lịch mà không có pasport vậy.
Data Scraping và Data Crawling
Hai khái niệm này thường dễ bị nhầm lẫn. Thuật ngữ Scraping dữ liệu không nhất thiết là bạn phải thu thập dữ liệu trên web, có thể là việc trích xuất thông tin từ máy chủ hoặc một trung tâm cơ sở dữ liệu. Thuật ngữ Crawling cũng có nghĩa là thu thập dữ liệu trên web, điều khác biệt rõ giữa hai khái niệm này chính là về mức độ và quy mô thu thập dữ liệu.
Với Web Crawling bạn có thể không biết các URL cụ thể và bạn cũng có thể không biết các địa chỉ tên miền. Và đây là lý do bạn thu thập thông tin: bạn muốn tìm các URL để bạn có thể làm gì đó với chúng sau này. Ví dụ: các công cụ tìm kiếm thu thập dữ liệu web để chúng có thể lập chỉ mục các trang và hiển thị chúng trong kết quả tìm kiếm.
Nhưng mặt khác với Web Scraping là khi bạn có một trang web mà bạn muốn trích xuất dữ liệu, trong trường hợp này là bạn biết miền, nhưng bạn không có URL trang của trang web cụ thể đó. Vì vậy, bạn không biết những trang nào để Scraping. Vì vậy, trước tiên, bạn tạo một trình thu thập thông tin sẽ xuất ra tất cả các URL trang mà bạn quan tâm, nó có thể là các trang trong một danh mục cụ thể trên trang web hoặc trong các phần cụ thể của trang web. Hoặc có thể URL cần phải chứa một số loại từ chẳng hạn và bạn thu thập tất cả các URL đó - và sau đó bạn tạo một trình quét trích xuất các trường dữ liệu được xác định trước từ các trang đó.
Tóm lại chúng ta có thể dựa trên những tiêu chí rõ ràng bên dưới để phân biệt cụ thể về dữ liệu :
| Data Scraping | Data Crawling |
|---|---|
| Liên quan đến việc trích xuất dữ liệu từ nhiều nguồn khác nhau bao gồm cả web | Đề cập đến việc tải xuống các trang từ web |
| Có thể được thực hiện ở mọi quy mô | Chủ yếu được thực hiện ở quy mô lớn |
| Sự trùng lặp không nhất thiết phải có | Rất nhiều sự trùng lặp bên trong dữ liệu |
| Cần tác nhân thu thập thông tin và trình phân tích cú pháp | Chỉ cần tác nhân thu thập thông tin |
Tìm hiểu cách khai thác
Để có thể thành công Scraping dữ liệu của một trang web, việc tìm hiểu trước trang web chính đó là một phần cốt lõi cũng như lên phương án chuyển từ làm tay sang sử dụng máy móc mà thôi.
Nhìn chung, trên trang BIMObject , bạn có thể dễ dàng thấy các hình ảnh bố trí theo từng ô bao gồm các thông tin như tên family, hình ảnh và chi tiết của chúng, sau đó là một nút tải về bên dưới mỗi khung. Việc tìm kiếm rất đơn giản bạn chỉ cần vào trang web gõ thông tin tìm kiếm bạn muốn và nhấn tìm kiếm, trang web sẽ trả về hàng loạt các thông tin được phân loại theo chữ cái tìm kiếm đó.
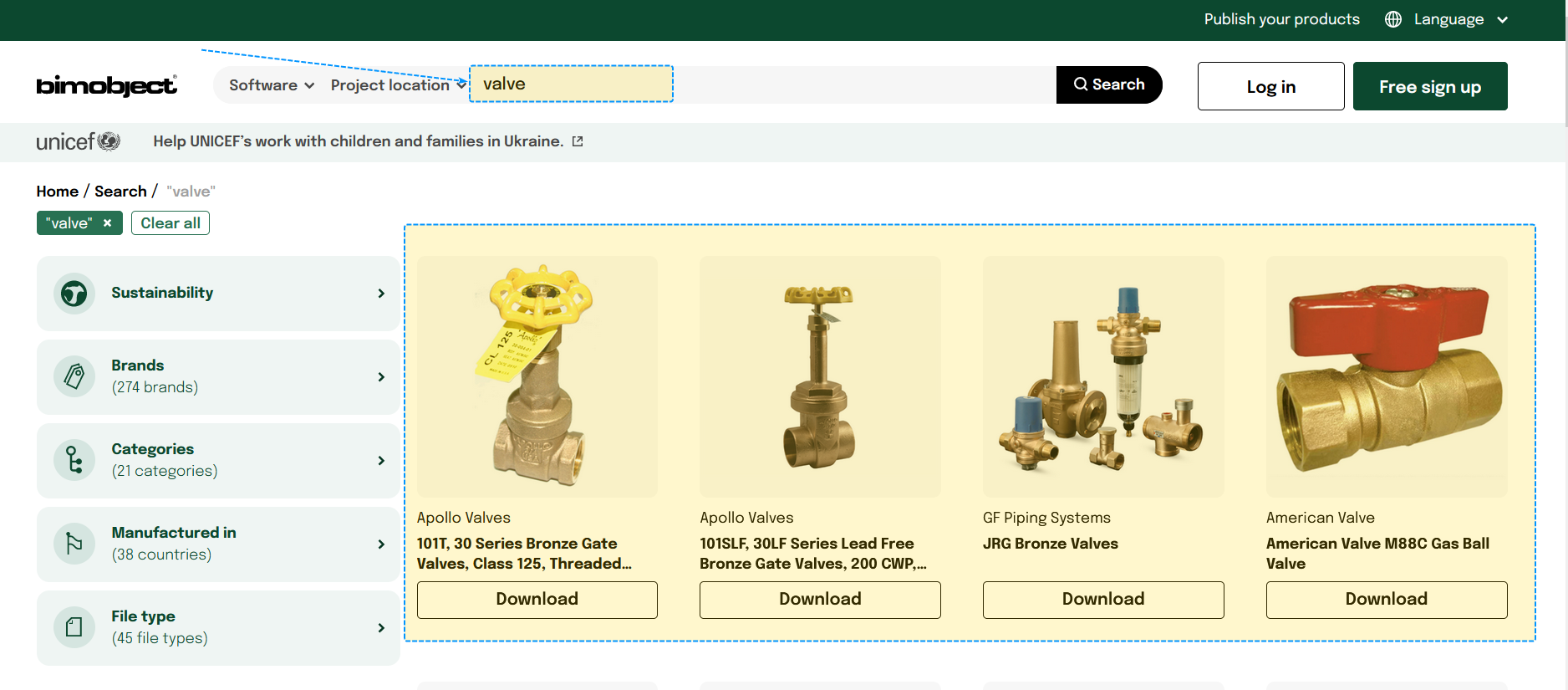
Như vậy việc bây giờ chính là kiểm tra thông tin đường dẫn của hình ảnh. Dễ dàng nhận ra thông qua việc xem thẻ của một trang web, các liên kết ảnh đa số sẽ nằm trong thẻ img. Như vậy công việc đơn giản của chúng ta chỉ cần là lấy về tất cả các liên kết đó và lưu trữ chúng.
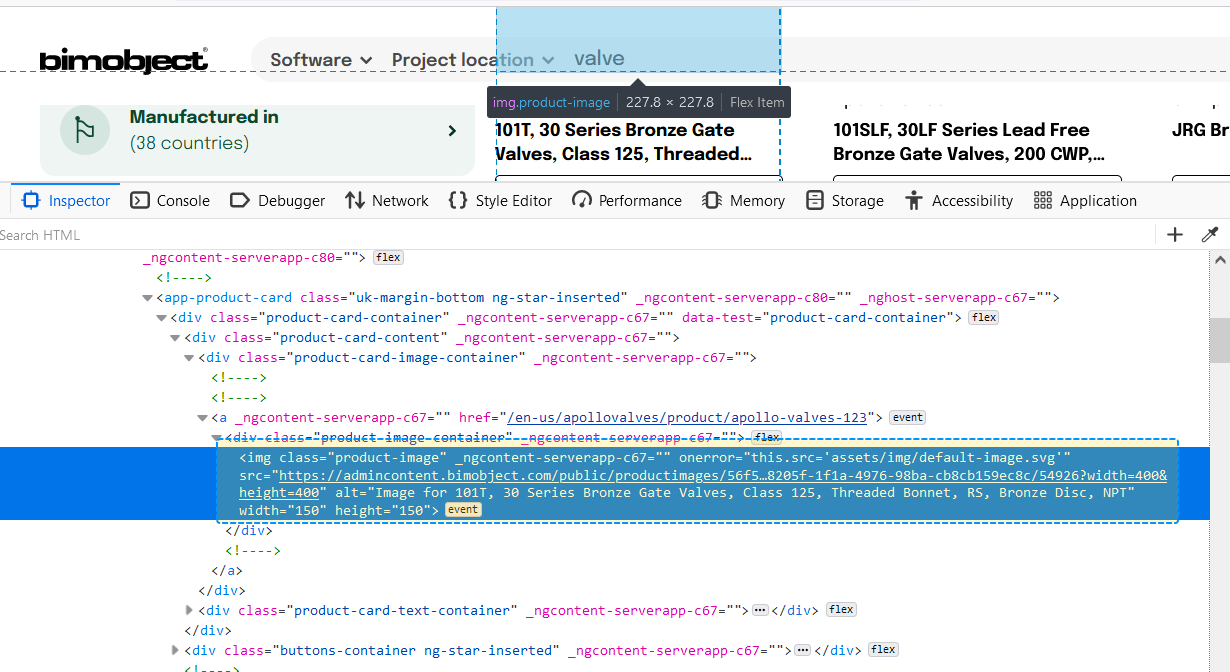
Quan sát kỹ hơn một chút, bạn sẽ thấy không phải tất cả thẻ img là thẻ chứa thông tin ảnh mà ta tìm kiếm. Đôi khi nó chính là các biểu tượng, các nhãn thông tin của một trang web, chẳng hạn như logo của trang web, đó cũng là thứ mà ta nên viết thêm trường hợp để loại bỏ chúng.
Vậy làm thế nào để có thể cào hết đữ liệu có được cuả giá trị mà chúng ta đang tìm kiếm ? Cũng như cách làm tay, bạn sẽ phải cuộn qua từng trang để lằm điều này.Như vậy việc của chúng ta chính là biết được số trang và tự động cuộn chúng để lấy toàn bộ và lưu ảnh xuống dưới máy. Như hình ảnh bên dưới, ta dễ dàng biết được số trang bắt đầu cuộn chính là 1 và kết thúc trang cuộn là 244, vậy sẽ có khoảng 244 lần cuộn trang để lấy hết thông tin dữ liệu chứ từ khóa là value như đã định sẵn ban đầu.

Một điều nữa là các ảnh của trang web không phải là png, chúng là định dạng webp, vì vậy chúng ta cũng cần phải tìm ra cách để chuyến chúng về jpg hoặc png. Thông tin chi tiết thêm cho bạn về Webp, chúng là một định dạng hình ảnh hiện đại cung cấp tiêu chuẩn nén chất lượng cao cho hình ảnh trên web, định dạng này nén ảnh nhỏ hơn 26% so với định dạng PNG và nhỏ hơn 25-34% so với định dạng JPEG. Trang web của mình cũng đang sử dụng định dạng webp để tăng tốc độ tải trang sao cho nhanh nhất, bạn cũng có thể tìm hiểu thêm về định dạng này tại https://developers.google.com/speed/webp.
Lên phương án
Như vậy sau khi đã tìm hiểu sơ qua trang web, thông tin như vậy đủ để ta có một quy trình như sau để tải toàn bộ ảnh:
Tìm kiếm chủ đề mình mong muốn trên trang BIMObject
Tìm ra tổng số trang muốn cuộn để lấy toàn bộ hình ảnh.
Tìm ta thẻ img trong mỗi trang và loại bỏ các thẻ không mong muốn.
Đọc thông tin liên kết để lấy ảnh.
Chuyển đổi định dạng ảnh và lưu trữ.
Hoàn tất và sửa lỗi nếu có.
Thử nghiệm mã
Với những quy trình bên trên, việc của chúng ta bây giờ là lựa chọn công nghệ để tự động chúng. Python được lựa chọn là ngôn ngữ để làm điều này vì chính từ sự phong phú đa dạng trong các thư viện khoa học dữ liệu cũng như các thư viện hỗ trợ trong việc Scraping data, BeautifulSoup chính là thư viện sẽ sử dụng để lấy thông tin các thẻ.Sử dụng !pip install bs4 để cài đặt package.
Trong quá trình lấy thẻ, sẽ có một số thẻ không phải là liên kết ảnh cần đến, bạn có thể sử dụng thư viện validators cài dặt với cú pháp pip install validators để kiểm tra nhanh. Vậy là ta có thể nhanh chóng lấy về các liên kết của hình ảnh trong cùng một trang, thử viết một hàm kiểm tra thử. Bên dưới mình sử dụng thêm thư viện pandas để hiển thị series cho tiện
from bs4 import BeautifulSoup
import validators
def geturlimg(url):
urls=[]
page = requests.get(url).text
soup = BeautifulSoup(page, 'html.parser')
for raw_img in soup.find_all('img'):
link = raw_img.get('src')
flag = validators.url(link)
if flag:
urls.append(link)
return urls
urls = geturlimg('https://www.bimobject.com/en-us/search?fullText=valve&sort=trending&page=1')
pd.Series(urls).head()
Đã lấy được liên kết ảnh, giờ việc tiếp theo là chuyển đổi định dạng ảnh nữa. Mình sử dụng phương pháp kết hợp thư viện PIL đẻ mở ảnh và chuyển đổi, requests để gọi ảnh từ liên kết về và BytesIO cho wrap ảnh từ request. hàm display là hàm được sử dụng thường xuyên và mục đích sử dụng bên dưới là để xem trước ảnh nhanh mà không cần phải vào thư mục để kiểm tra nữa.
# test save image
print("test save image url",urls[0])
from urllib import request
from io import BytesIO
from PIL import Image
img_url= urls[0]
# url -->content --> wrap it for BytesIO --> open as Image and then convert
img=Image.open(BytesIO(requests.get(img_url).content)).convert("RGB")
#img.show()
# img.save("imgs/Test.png")
display(img)
Như vậy bạn có thể dễ dàng đóng gói chức năng này dưới một hàm để dễ sử dụng cho sau này.
from PIL import Image
def download_img(url,name):
img=Image.open(BytesIO(requests.get(url).content)).convert("RGB")
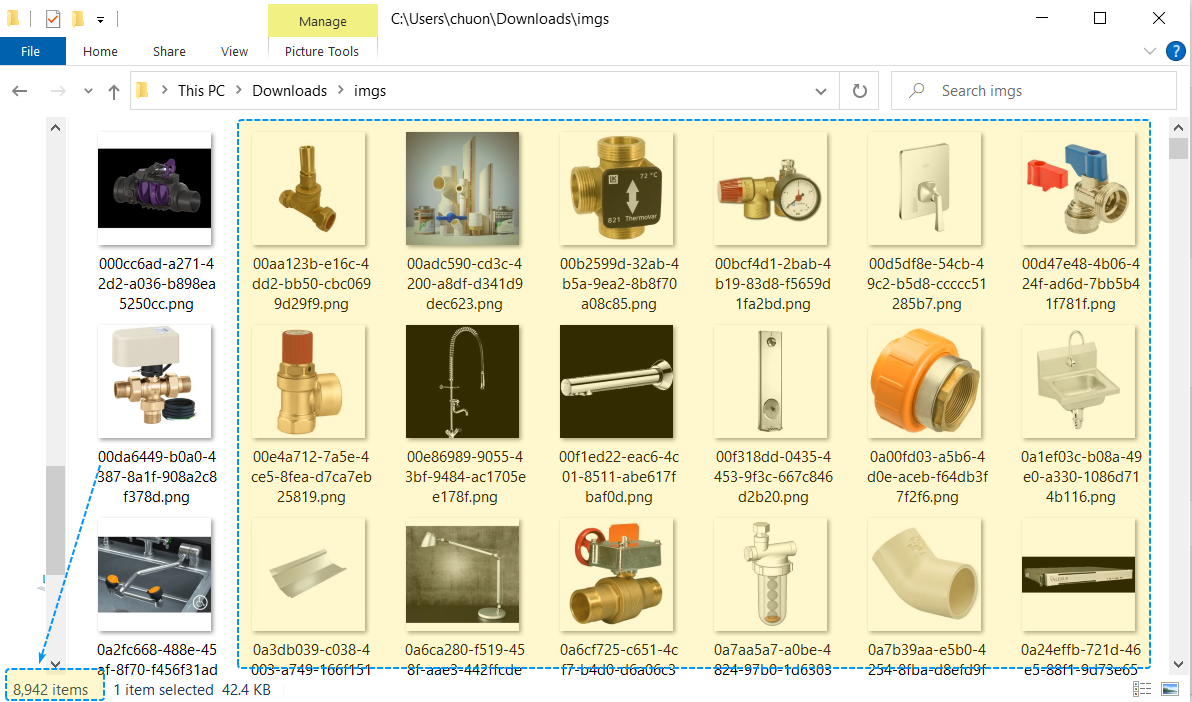
img.save(name+".png")Cuối cùng hơn hết đó chính là quyết định số trang cuộn và cào thôi. Ở đây mình sẽ tạo một thư mục con là imgs để lưu toàn bộ ảnh, số lượng trang cuộn là 244, và mỗi ảnh sẽ được lưu dưới mã Guid để tránh bị trùng lặp.
import uuid
pagecount = 224
mainurl = "https://www.bimobject.com/en-us/search?fullText=valve&sort=trending&page="
folder_name = "imgs"
flag = os.path.exists(folder_name)
if flag == False:
os.mkdir(folder_name)
for page in range(pagecount):
page +=1
url = mainurl + str(page)
urlimages = geturlimg(url)
for uri_img in urlimages:
# create random guid
guid = uuid.uuid4()
download_img(uri_img,f"{folder_name}/{guid}")Cuối cùng sau một thời gian đợi mòn mỏi thì mình cũng cào được khoảng gần 9000 bức ảnh, thôi tiếp tục chuyển đến chỗ khác 😬
Tương tự với cách tìm kiếm cho valve, bạn cũng có thể thử tìm kiếm và cào thông tin khác như chair chẳng hạn, có vẻ sẽ có nhiều hình ảnh đẹp hơn.
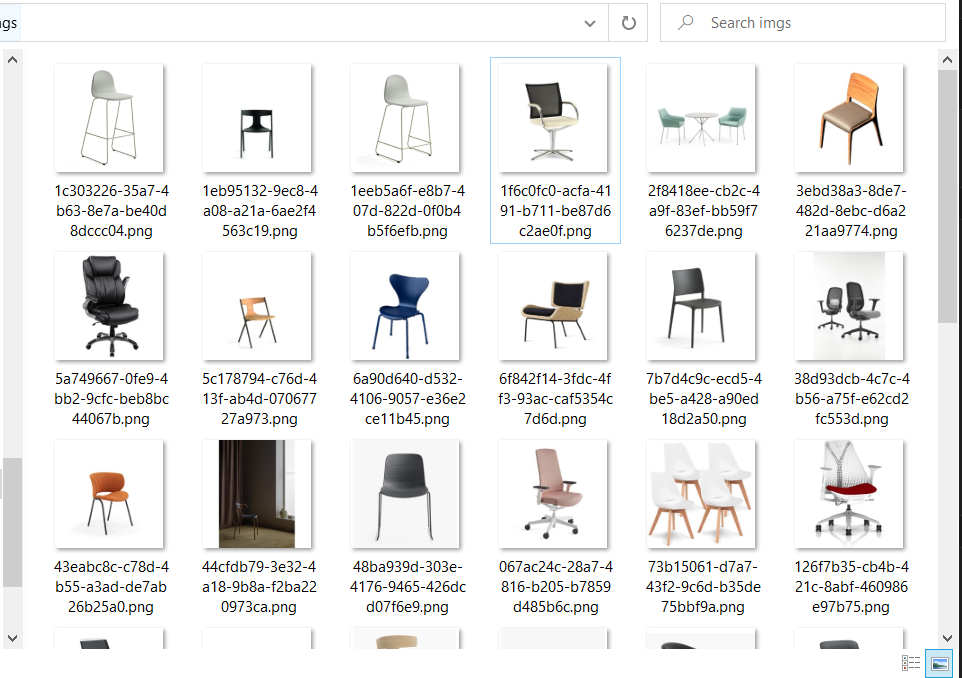
Bạn cũng có thể nhóm bức ảnh theo hàng, mỗi hàng 5 đến 6 ảnh để xem trước hoặc trình bày cho đẹp
import matplotlib.pyplot as plt
def show_images(tdir):
filelist=os.listdir(tdir)
length=len(filelist)
columns=5
rows=int(np.ceil(length/columns))
plt.figure(figsize=(20, rows * 4))
for i, f in enumerate(filelist):
if i >=10: break
fpath=os.path.join(tdir, f)
imgpath=os.path.join(tdir,f)
img=plt.imread(imgpath)
plt.subplot(rows, columns, i+1)
plt.axis('off')
plt.title(f, color='blue', fontsize=5)
plt.imshow(img)
show_images("imgs2")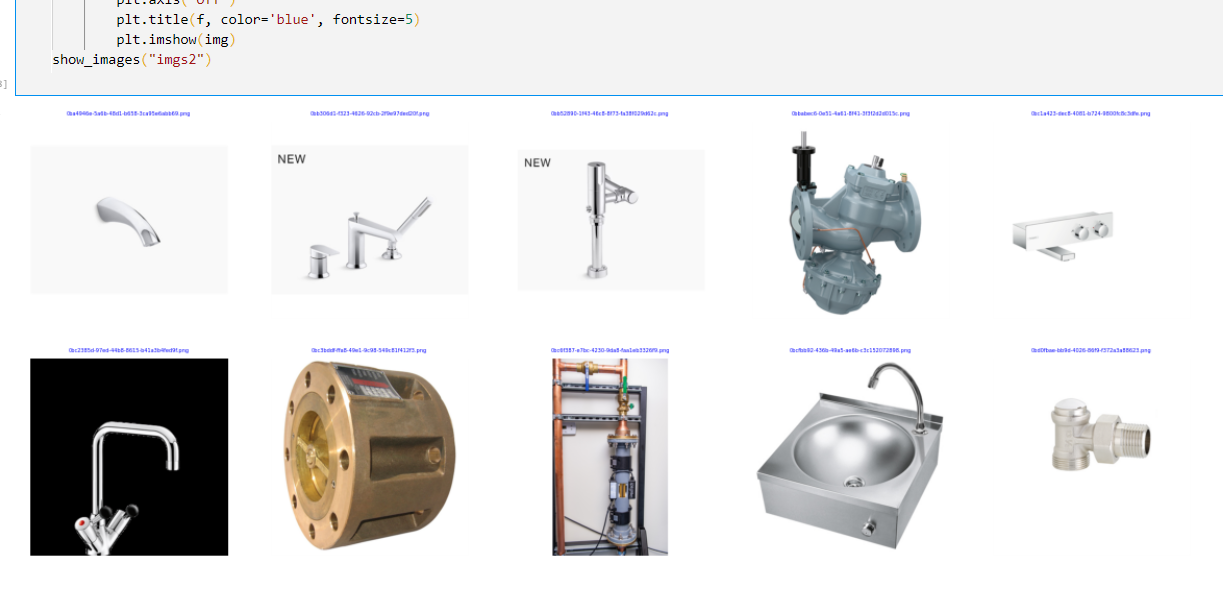
Mở rộng
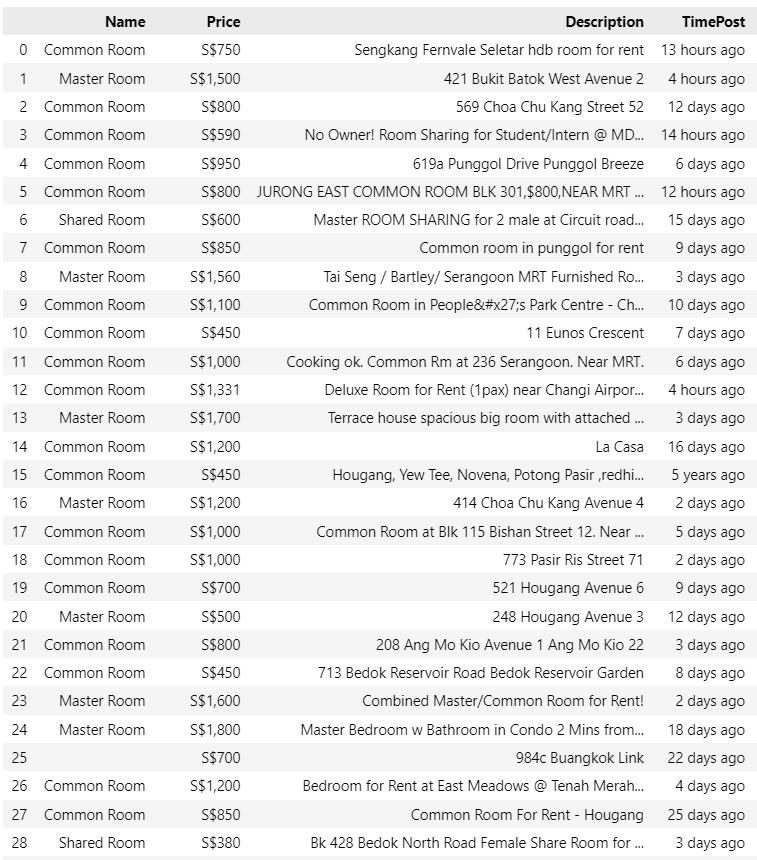
Bạn cũng có thể nghĩ một vài ý tưởng chung chung để mở rộng như vấn đề và học thêm vài điều từ cuộc sống như một ví dụ điển hình của mình. Lúc mình mới đến Singapore, nhờ vào Crawling data của trang carousell mà mình cũng phần nào về các loại phòng cho thuê và giá cả ở đây. Đấy, đôi lúc lấy kiến thức ra áp dụng thực tế thì cũng thấy hữu ích đó chứ.
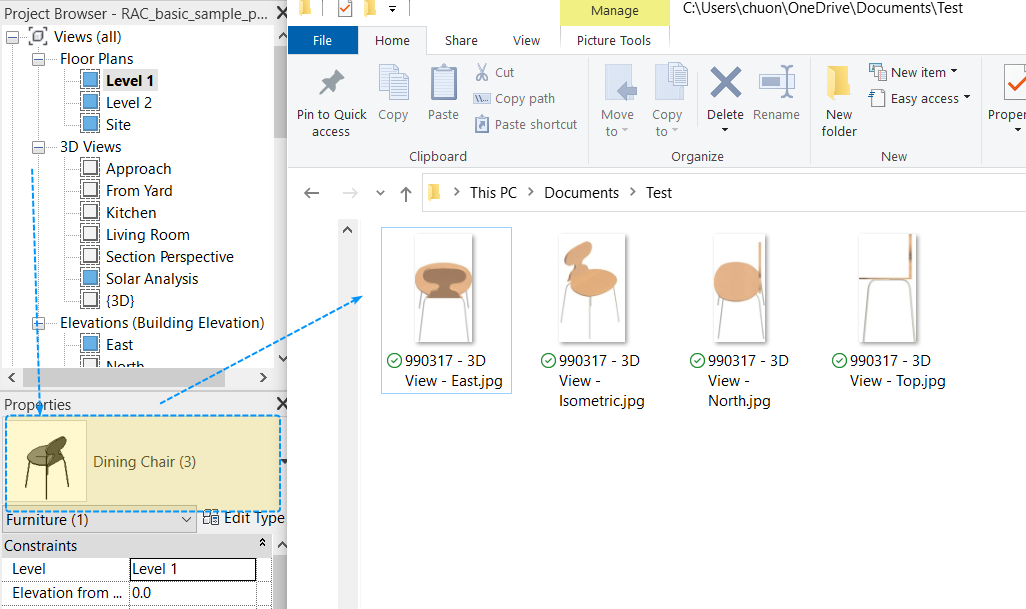
Một dự án GetElementImage của tác giả jeremytammik cũng là một dự án khá hay ho để nghiên cứu, dự án cho phép bạn trích xuất hình ảnh của một family Revit ở bốn đến 5 góc độ với render rất đẹp, bạn có thể tham khảo thêm.
Tổng kết
Hi vọng qua bài này giúp bạn có cái nhìn tổng quan về việc Scraping dữ liệu của một trang web. Bạn có thể áp dụng cách tương tự để cào những thứ bạn thích như ô tô, nhà cửa, hay thậm chí một cô gái lang thang trên google, nhưng hãy lưu ý rằng, băng thông của một trang web là có hạn và việc bạn cào dữ liệu liên tục như vậy sẽ ảnh hưởng rất nhiều đến lưu lượng trang web. Việc làm dụng quá nhiều đôi khi bạn sẽ bị trang web chặn không cho truy cập nữa.
Vì vậy không làm dụng cho mục đích xấu mà sử dụng cho học thuật là chính. Bạn có thể chia thời gian nghỉ ngơi để máy tự cào dữ liệu hoặc chia nhỏ thời gian chạy, tác giả không chịu trách nhiệm cho bất cứ hành động kháng cáo hoặc yêu cầu gỡ bỏ bài viết.
Mã nguồn tham khảo đặt tại SraperBIMObject.ipynb
Cuộc sống ở Singapore
Hôm nay chạy xuống khu Funan thử ăn ẩm thực Nhật Bản ở quán này, cảm giác ăn rất giống hương vị của các món ăn ở Việt Nam, những món này họ thường không lạm dụng quá nhiều gia vị nhưng vẫn mang lại mùi của món ăn rất ngon.
